
Простая объектная СУБД
В рамках одного проекта была поставлена задача долговременного хранения логически связанных объектов данных с обеспечением многопользовательского доступа к их содержимому. Возможны различные способы удовлетворения этой потребности средствами уже существующих систем управления данными. Тем не менее, был предпринят поиск простого и производительного решения, результаты которого и предлагаются к рассмотрению.
В данной статье рассматривается общая логика управления данными, без погружения в детали программной реализации, зачастую самоочевидные.
По условиям задачи система управления объектной базой данных, а точнее та ее часть, которая отвечает за многопользовательский доступ, оперирует однородным множеством изолированных объектов. Отметим, что унифицированную форму объекта могут принимать в общем-то самые различные информационные сущности: данные, мета-данные, списки, транзакции, сценарные ресурсы, документы и прочие.
Изначально об объекте известно только то, что он сериализован, в целях долговременного хранения на диске, и состоит из двух частей: заголовка и собственно содержимого.
Заголовок объекта имеет фиксированную длину, и необходим для размещения в нем служебной информации. В частности, в заголовке хранится полная длина объекта в байтах, его собственный дескриптор и номер состояния.
Априори объект содержит набор значений, которые идентифицируются по их порядковому номеру в наборе. Сам объект свои значения никак не интерпретирует, но "знает", что каждое значение характеризуется длиной в байтах, что позволяет вычислить размер объекта. Набор значений существует в формате кортежа.
Для хранения объектов используется условно бесконечное файловое пространство, логически разбитое на кластеры. В файловом хранилище каждый объект занимает один или более последовательных кластеров. Порядковый номер первого кластера используется в качестве файлового указателя FP (File Pointer) на размещение объекта в хранилище.
Для долговременного хранения файловых указателей используется таблица аллокации DAT (Data Allocation Table), которая представляет собой простой динамически расширяемый массив целочисленных указателей. Индексы ячеек DAT используются в качестве системных идентификаторов объектов IDO. Когда создается новый объект, ему выделяется очередная свободная ячейка DAT, индекс которой становится постоянным идентификатором объекта. Этот идентификатор является уникальным и глобальным дескриптором объекта в пределах физической базы данных.
При старте системы DAT загружается из хранилища в оперативную память, и используется для организации быстрого доступа к объекту по его IDO по следующей схеме:
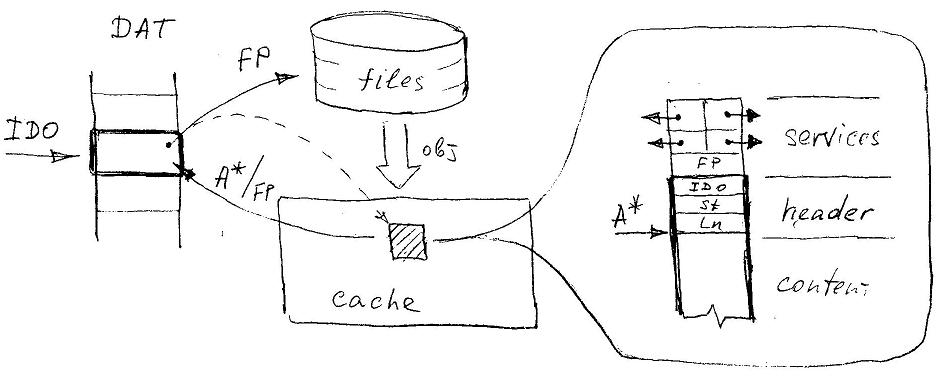
Если извлеченное из DAT значение представляет собой файловый указатель, то объект загружается из хранилища в память - Cache объектов, и содержимое ячейки DAT подменяется указателем на память A*. Обратная замена происходит при вытеснении объекта из памяти.
Обратим внимание: указатель на память A* — это не абсолютный адрес, а лишь смещение относительно начала Cache, но указывает он непосредственно на содержимое объекта. Заголовок объекта, а также служебные поля, предназначенные для временного хранения FP и связывания объектов в цепочки, расположены относительно A* с отрицательным смещением. Примечательно, что значение A* также используется в качестве идентификатора объекта в памяти.
Представляет собой непрерывную область памяти, статически выделенную при инициализации системы. Требуемый размер задается опционально.
Основные задачи Cache — быть максимально наполненным, и быстро выделять требуемое для размещения объекта пространство. Для этих целей цепочка блоков свободной памяти ранжирована, а выталкивание очередных неиспользуемых объектов происходит только тогда, когда это единственный способ получить свободное пространство требуемого размера. При выделении памяти объекту автоматически учитывается необходимый резерв для размещения служебных полей. А для организации управления свободной памятью она же и используется.
В отсутствие внешних воздействий полное множество объектов, образующих базу данных, бесконечно долго сохраняет неизменным свое состояние. Любое действие по извлечению содержимого объектов, не изменяющее состояние базы данных, далее понимается как выборка.
Внешнее воздействие, изменяющее состояние базы данных, рассматривается как транзакция.
Транзакция создает новые объекты или изменяет содержимое уже существующих. При этом задействован следующий механизм внесения изменений: предварительно создается копия объекта, на правах его более старшей версии, в которую эти изменения и вносятся. Совокупность вновь созданных объектов и измененных копий объектов образует множество объектов транзакции. Соответственно, новое состояние базы есть объекты транзакции + объекты предыдущего состояния, с игнорированием более младших версий объектов. Де-факто, последовательный номер транзакции и есть номер состояния базы.
В условиях многопользовательского доступа к данными требуются определенные усилия по сохранению логической целостности данных — как при исполнении транзакций, так и во время выборки.
Концепция транзакционной целостности общеизвестна — "все, или ничего".
Новое состояние базы данных будет образовано только в случае успешного завершения транзакции. При этом объекты транзакции становятся общедоступными. Фиксация нового состояния происходит, когда пользователь завершает транзакционную сессию, которую должен открыть перед началом исполнения транзакции. Но пока транзакционная сессия не завершена, порождаемые или изменяемые ею объекты доступны исключительно тому пользователю, который открыл сессию. Любое прерывание транзакционной сессии, независимо от причины прерывания, повлечет за собой простое уничтожение порожденных сессией объектов.
Помимо сказанного, следует учитывать еще одно очевидное правило: транзакция, начатая позже предыдущей, не может быть завершена раньше завершения предыдущей, более приоритетной транзакции.
Необходимость соблюдения "состоятельной" целостности данных далеко не столь очевидна.
Формируется оперативный финансовый отчет компании, для чего делается весьма обширная по объему и протяженная во времени выборка данных. В это же самое время база непрерывно меняет свое состояние под воздействием потока транзакций. Если не вводить ограничений, то существует совсем не нулевая вероятность того, что баланс отчета не сойдется, так как в выборку (случайным по пересечению интервалов времени образом) попала только часть в общем-то правильной и успешно завершенной проводки. Чтобы пресечь такую коллизию необходимо следовать простому правилу — любая выборка данных должна осуществляться при неизменном состоянии базы. Фиксацию состояния пользователь реализует, открывая сессию выборки. В рамках этой сессии игнорируются все последующие состояния базы данных, то есть более старшие версии объектов.
Таким образом, в каждый момент времени единичный пользователь или не делает ничего, или находится в процессе исполнения одной из двух сессии: транзакционной или выборки.
Как минимум одно состояние базы данных — фоновое, актуально всегда. Фоновое состояние образовано полным множеством объектов из DAT, из которых часть осталась на диске, а часть загружена в память.
Динамика многопользовательского процесса такова, что пользователи, исполняя транзакции, порождают последовательность новых временных состояний базы данных. При успешном завершения очередной транзакционной сессии порожденное ею временное состояние становится общедоступным. При открытии сессии выборки пользователю предоставляется доступное состояние с самым большим номером. Просуществовав некоторое время, временные состояния, более не используемые в целях выборки, последовательно поглощаются фоновым состоянием.
Любое состояние, включая фоновое, владеет некоторым множеством объектов состояния, которые связаны в одноименную цепочку. Обратим внимание: объекты временных состояний — это упомянутые выше объекты транзакции, ставшие актуальными в результате успешного завершения транзакционной сессии. В цепочке фонового состояния объекты упорядочены по убыванию времени их неиспользования. Обращение к объекту за его содержимым автоматически перемещает объект в конец цепочки. Объекты в начале цепочки — кандидаты на вытеснение из памяти Cache.
Ранее упоминалось, что попытка изменить существующий объект автоматически порождает его новую версию. Таким образом, одновременно в памяти могут находится несколько версий одного и того же объекта. Эти версии связаны в одноименную цепочку. Указатель (A*) на первый объект в цепочке версий находится в DAT, а сама цепочка позволяет пользователю получить доступ к "правильной" версии объекта в требуемом состоянии. При этом корректной (актуальной с точки зрения пользователя) считается версия с наибольшим номером состояния, не превышающим требуемый.
Распределение по состояниям объектов, связанных в цепочки состояний и версий, выглядит как-то так:
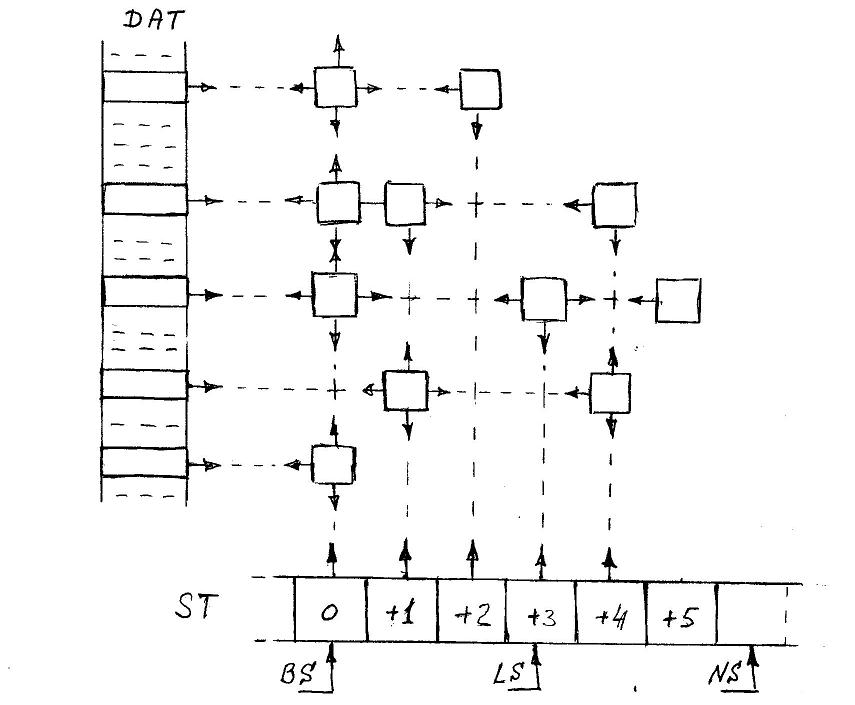
Процесс поглощения состояния инициируется последним из использовавших его при завершении сессии. При поглощении очередного временного состояния, фоновое состояние (Background) сначала удаляет из памяти устаревшие версии объектов, для которых есть новая версия в поглощаемом состоянии, после чего попросту присоединяет цепочку объектов поглощаемого состояния к своей.
Для управления многопользовательским доступом, состояниями базы данных и их объектами используется таблица состояний ST (States Table).
Каждая запись ST содержит указатель (A*) на первый объект цепочки объектов состояния, идентификаторы пользователя и объекта блокировки, а также счетчик пользователей, использующих это состояние.
Применительно к таблице ST действуют три внешних указателя, оперирующих полным номером состояния базы данных. Если размер таблицы кратен степени числа два, то использование младших разрядов абсолютного номера в качестве индекса к таблице ST обеспечивает круговое перемещение указателей по таблице.
Указатель Background State (BS) содержит номер фонового состояния. При поглощении последующего временного состояния указатель BS инкрементируется. Условием поглощения является нулевое значение счетчиков использования сразу двух состояний: фонового и следующего за ним. Условие проверяется при закрытии любой из сессий, после декремента счетчика использования.
Указатель Last Available State (LS) содержит номер самого старшего состояния из доступных. Этот номер предоставляется пользователю при открытии им сессии выборки. Когда очередная транзакционная сессия закрывается, указатель LS инкрементируется, автоматически получая номер этой сессии.
Указатель Next State (NS) предоставляет номер состояния пользователю, открывающему транзакционную сессию, после чего инкрементируется. Если открытых транзакционных сессий нет, то значение NS превышает значение LS на 1. Если нет временных состояний, то значения указателей BS и LS совпадают.
Номер состояния, получаемый пользователем при открытии любой сессии, сохраняется в соответствующей записи таблицы клиентов CT (Client Table). Все обращения пользователя к API сервиса объектов включают в себя идентификатор клиента, а остальные данные извлекаются из соответствующей записи CT.
Системный идентификатор клиента - это порядковый номер записи, выделенной ему в Client Table при авторизации. В этой таблице регистрируются как системные ресурсы, выделенные клиенту: дескрипторы TCP-сокета и потока, так и ресурсы, используемые им в системе управления данными, и в частности - номер открытого пользователем состояния, а также различные управляющие флаги.
Напомним: транзакции, независимо от их продолжительности и результата, должны завершаться строго в том порядке, в котором они были начаты, по возрастанию собственных номеров. Для организации такой очередности используется пул именованных объектов блокировки, которые создаются совместно с таблицей ST при инициализации системы.
Непосредственно при открытии транзакционной сессии, из пула запрашивается свободный объект блокировки, который немедленно захватывается потоком пользователя, и удерживается им до полного завершения сессии. Идентификатор захваченного объекта блокировки сохраняется в соответствующей состоянию записи ST. После чего проверяется запись предшествующего состояния на предмет наличия незавершенной транзакции в виде актуального идентификатора объекта блокировки.
При параллельном исполнении транзакций всегда существует неприятная вероятность того что более ранняя транзакция изменит содержимое объекта уже после того, как последующая транзакция использует этот же объект в своих целях. Накладные расходы на перманентное отслеживание такого конфликта весьма велики. А его разрешение возможно только путем пере-исполнения всех последующих транзакций.
При наличии предыдущей незавершенной транзакции, текущая, пытаясь избежать конфликта, меняет логику своего исполнения. Вспомним, что обращение к диску является самой продолжительной из всех операций, выполняемых сервисом объектов. Поэтому, пока предыдущая транзакция исполняется, текущая только лишь имитирует свое исполнение - без реального создания копий объекта и изменения их содержимого. При этом все объекты, которые так или иначе были использованы транзакцией, гарантировано окажутся загружены в Cache. Когда имитационное исполнение завершено, то транзакция повторно проверяет запись ST предыдущего состояния. Если идентификатор объекта блокировки из нее получен, то транзакция "зависает" в попытке захватить этот объект. После освобождения объекта блокировки предыдущей транзакцией, текущая продолжит свое исполнение, но теперь уже в штатном режиме и с минимальным временем исполнения.
Если что-то пошло не так (например, фатальная ошибка сервиса объектов или аппаратный сбой), то спасти базу данных может только авто-восстановление из контрольной точки. В более же мягком случае, когда поток клиента "упал и не отжался", или ушел в бесконечность, оставив свою сессию открытой, остановку конвейера состояний можно предотвратить.
Зависание транзакционной сессии обнаружится, когда новая транзакция не сможет получить свободный объект из пула, который именно для этих целей содержит вполовину меньше объектов блокировки, чем таблица ST записей. В данном случае проблемным является состояние с индексом [LS+1].
Зависание сессии выборки будет обнаружено только тогда, когда исчерпаются все свободные записи ST, то есть когда индексы BS и NS сравняются. Зависшее состояние с индексом [BS] или [BS+1] будет иметь не нулевое значение счетчика использования.
Безотносительно причины аварии сессии, ее последствия всегда одинаковы: после получения идентификатора "зависшего пользователя" его поток принудительно останавливается, все использованные ресурсы освобождаются, сессия принудительно завершается, после чего конвейер самостоятельно разгружается уже в штатном режиме. Все эти действия выполняются в потоке пользователя, обнаружившего проблему. По завершении восстановительных операций поток зависшего пользователя запускается снова, и он предпринимает как минимум одну попытку повторить неудачную сессию заново. В случае второй неудачи пользователь начинает свой поток с ожидания внешних событий. Весь этот процесс регулируется флагами, выставляемыми пользователю в Client Table.
Содержимое объекта — набор его значений, хранится в формате кортежа. Свойства кортежа позволяют использовать его в качестве универсального, с точки зрения хранения и доступа, способа организации данных. Стоит упомянуть, что менеджер памяти сервиса объектов, обеспечивающий работу всех его частей, включая Cache объектов, изначально ориентирован на поддержку формата кортежа.
Логически, кортеж представляет собой последовательность элементов, идентифицируемых по их порядковому номеру в кортеже. Элемент кортежа содержит некоторое значение, которое характеризуется своей длиной. Длина значения априори известна, и вынесена в заголовок значения. Реализуется кортеж в виде массива относительных указателей. Каждый указатель представляет собой смещение начала значения относительно начала кортежа. И смещение, и размеры измеряются в байтах.
Кортеж обладает рядом замечательных свойств.
Прежде всего, значением в кортеже может быть другой кортеж. С этой точки зрения все содержимое объекта можно рассматривать как одно значение. Длина любого значения известна из его заголовка, а значит известно и количество элементов в кортеже.
Порядок следования элементов в кортеже строг и неизменен. Операция "Вставка" запрещена. Но можно безболезненно добавлять к имеющемуся набору новые элементы.
В кортеже не инициализированное значение будет иметь нулевое значение смещения, чем и отличается от "пустого" значения с нулевой длиной. Не инициализированным значением можно бесконфликтно оперировать, в том числе рассматривая его как "пустое" значение.
В кортеже можно разместить структуру данных произвольной сложности. Логически, формат кортежа напоминает XML, но только с индексами вместо тегов и возможностью оперировать не только текстовыми значениями. К отдельному значению в сложной структуре можно обратится напрямую, используя в качестве адреса последовательность индексов (маршрут). А можно и относительно кортежа-владельца.
Кортеж обладает способностью создавать свои собственные экземпляры. Экземпляр кортежа отличается от его же копии нулевыми значениями смещения для всех его значений, не являющихся в свою очередь кортежами. Иными словами, экземпляр — это копия структуры.
Кортеж значений может существовать как в сериализованной форме (непрерывный набор байт для хранения на диске), так и в произвольной, при которой отдельные значения кортежа размещены в разных местах оперативной памяти. Смещение относительно начала кортежа может иметь в том числе и отрицательную величину.
Две последние из перечисленных особенностей поведения кортежа активно используются при модификации объекта в ходе транзакционной сессии.
Собственно говоря, под изменением объекта понимается модификация одного или нескольких его значений. Хотя ранее упоминалось, что для внесения изменений создается копия объекта, на самом деле нет необходимости копировать объект в полном объеме. Вместо его копии в Cache создается экземпляр объекта с обнуленными указателями в кортеже. При обращении к такому не инициализированному значению, в качестве результата возвращается значение, извлеченное из предшествующей версии объекта (экономим память).
Новое значение, присваиваемое объекту, также размещается в Cache. Тому все едино, что объект, что отдельное значение. Смещение нового значения относительно экземпляра объекта записывается в соответствующий элемент кортежа.
Далее, в случае успешного завершения транзакции, сформированные таким образом объекты транзакции необходимо выгрузить на диск.
Файловое пространство, выделяемое для хранения объектов, не только кластеризовано, но и разбито на банки данных размером два в степени N кластеров. Каждый банк занимает один файл, который именуется последовательным номером банка. Таким образом, при обращении к объекту на диске, его FP последовательно конвертируется сначала в имя файла, а затем в номер кластера в файле.
Для минимизации дисковых операций, а также времени автоматического восстановления системы после аварии, все объекты, независимо от их первичного расположения, сохраняются в одном банке. Для этих целей резервируется непрерывная область памяти соответствующего размера (оптимально - 32 МБ), и в этот банк памяти последовательно записываются объекты транзакций, вплоть до его заполнения. Перед записью длина (в кластерах) всех объектов суммируется, и если свободного места в банке памяти недостаточно, у системы запрашивается новый банк, а заполненный ставится в очередь потока записи.
Сохранение объектов транзакции выполняется при закрытии транзакционной сессии. Запись объекта в память начинается с начала очередного свободного кластера, при этом формируется новый FP объекта. Новый FP не вычисляется, если предыдущая версия объекта уже присутствует в этой памяти, и ее размер позволяет записать на этом месте новую версию. В память записывается полная версия объекта со всеми значениями его кортежа, как измененными, так и заимствованными у предыдущей версии. В процессе записи объект сериализуется, с вычислением новых указателей (смещений) в кортеже.
После завершения сессии измененные объекты транзакции в Cache становятся общедоступны в том виде как есть, а именно - с неполным кортежем. Эти объекты должны заместить собой предыдущие версии.
Естественно, что если у объекта есть последующая версия в памяти, то такой объект не может быть вытеснен из Cache в целях получения свободного места, даже если он и стоит в самом начале цепочки вытеснения. Для такого объекта предусмотрен иной порядок вытеснения, а пока вместо него вытолкнут другого очередника.
Предыдущая версия объекта (далее, версия [0]) вытесняется из памяти своей последующей версией [+1], и происходит это в ходе поглощения временного состояния фоновым. И есть тут одна тонкость исполнения.
Версия [0], как правило подгруженная с диска, занимает непрерывную область в Cache, в то время как кортеж и новые значения версии [+1] находятся в разных местах, усиливая дефрагментацию памяти. Поэтому сценарий поглощения версии [+1] выглядит привлекательнее сценария вытеснения версии [0]. Если новое значение версии [+1] по размеру не превышает имеющееся, то оно просто копируется в тело версии [0], и занимаемая им память освобождается. Иначе это новое значение остается за пределами объекта как есть, и для него вычисляется новое смещение, а объекту выставляется флаг, обязывающий процесс обычного вытеснения анализировать объект на наличие фрагментов за его пределами.
В ходе исполнения транзакционной сессии транзакция формализуется в формат объекта. Элементы кортежа этого объекта образованы элементарными действиями, такими как создание объекта или изменение одного из его значений. В заголовке объекта помимо всего прочего сохраняются идентификатор пользователя, от имени которого исполнялась транзакция, а также отметка о дате/времени начала транзакции. Если транзакционная сессия завершается успешно, то при закрытии сессии формализованная таким образом транзакция ставится в очередь записи.
Стоит отметить, что порядок постановки в очередь транзакции и банка объектов, сформированных в ходе закрытия одной сессии, определяется тем, удалось ли разместить объекты транзакции в этом банке. Если удалось, то формализованная транзакция помещается в очередь первой. Если для размещения объектов данной транзакции был открыт новый банк, то первым в очередь ставится банк объектов.
Последовательность формализованных транзакций, сохраненных на диске, образует журнал транзакций.
Полный журнал транзакций представляет собой первичную событийную форму существования базы данных. Последовательное пере-исполнение содержимого журнала дает содержимое базы данных, полностью идентичное полученному в рабочем многопользовательском режиме. Эта особенность обуславливает использование журнала в качестве элемента обеспечения надежности.
Помимо этого стоит отметить, что у журнала есть еще одна функция – фискальная, которая не раз доказывала свою полезность в разборках типа " … это программа накосячила".
Сохранением данных на диске занимается поток записи - фоновый поток, обслуживающий файловое хранилище. Информацию о сохраняемых данных: указатель на область памяти, размер области и тип данных, поток записи извлекает из очереди. По окончании записи в файл поток самостоятельно освобождает переданную ему область памяти.
Тип данных определяет целевой файл, в который будут записываться данные. Основных типов данных всего три: формализованные транзакции, банки объектов и DAT.
Все транзакции поток записи пишет в один постоянно открытый файл журнала транзакций. В файле транзакции следуют одна за другой, без выравнивания. Перед записью транзакции вычисляется и фиксируется в заголовке ее контрольная сумма, а по окончании записи делается принудительный commit.
Когда очередь доходит до сохранения банка объектов, поток записи сначала создает очередную контрольную точку, и только потом записывает банк в файл. Для создания контрольной точки поток записи закрывает текущей файл журнала, упаковывает его в резервную копию, упаковывает содержимое банка в отдельный файл, упаковывает резервную копию полного DAT, и открывает новый файл журнала.
В результате действий потока записи файловое хранилище принимает следующий вид:
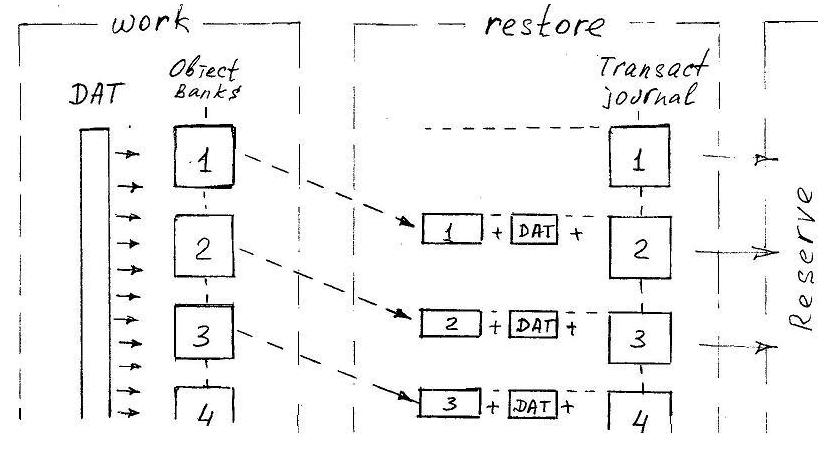
В рабочей области размещаются DAT и банки объектов. В области резервирования размещаются архивные копии банков объектов и файлы, совокупно образующие полный журнал транзакций. Каждый отдельный файл журнала транзакций вместе с архивной копией DAT, а также архивными копиями собственного и предшествующих банков объектов, образует отдельную контрольную точку.
В ходе инициализации файлового хранилища при старте системы выполняется проверка его валидности. Хранилище признается пригодным к работе, если контрольные суммы совпадают со значениями в заголовках файлов, а содержимое рабочей области соответствует содержимому области резервирования.
Если работа сервера не была завершена надлежащим образом, то как минимум DAT в рабочей области и последний файл журнала транзакций проверку не пройдут, и автоматически запустится процесс восстановления из самой последней контрольной точки.
Логика восстановления достаточно очевидна: из резервных копий банков объектов восстанавливаются отсутствующие или поврежденные банки, а затем из самой последней контрольной точки восстанавливается файл DAT, после чего последовательно исполняются транзакции из ее журнала. Так как сохранность самой последней транзакции в журнале не гарантирована, то при несоответствии контрольной суммы транзакции процесс завершается.
В нашем распоряжении всего два физических ресурса: память и такты процессора. А так как в приоритете производительность, то следствием является повышенный расход памяти. Так, с целью уменьшить объем файловых операций, новые и измененные объекты сохраняются на диске оптом, одним файлом. При этом более ранние версии изменяемых объектов остаются на прежних местах в предыдущих банках и уже никогда не будут использованы. Чтобы вернуть системе дисковую память, внутренне "поредевший" банк необходимо периодически "уплотнять", уменьшая его размер, и не забывая при этом внести изменения в DAT и перезаписать архивную копию банка. Для облегчения анализа заполненности банков, сервис объектов перманентно поддерживает в актуальном состоянии битовую карту кластеров.
Весь рассмотренный выше относительно несложный функционал группируется вокруг внутренних управляющих структур данных Файлового хранилища и Сервиса объектов. Файловое хранилище отвечает за надежность долговременного хранения данных, которую обеспечивает как многократным резервным копированием базы данных в различных ее формах, включая журнал транзакций, так и наличием механизмов авто-восстановления. Сервис объектов минимальными средствами обеспечивает многопользовательский доступ к содержимому базы данных.
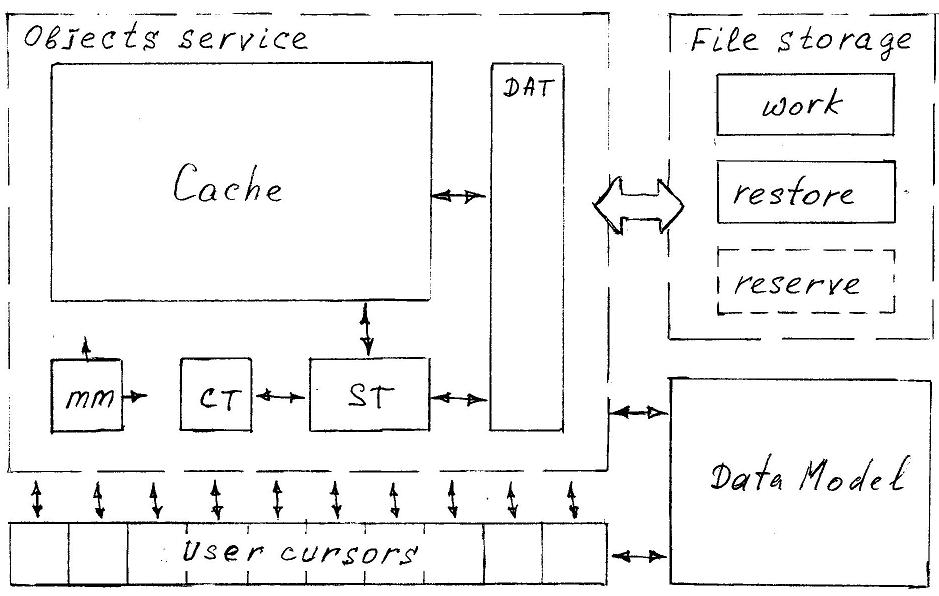
Модель данных средствами структурированных метаданных, также хранимых в формате объекта, обеспечивает логическую связанность и целостность объектов данных и их значений, в полном соответствии с бизнес-логикой приложения, интегрированной непосредственно в метаданные.
Слой пользовательских Курсоров, являющихся неким логическим подобием курсоров SQL, представляет собой серверную часть интерфейсных ресурсов, используемых для взаимодействия пользователя с содержимым базы данных. Этот слой, что очень важно, помимо всего прочего обеспечивает полную изоляцию интерфейса от внутренней системы идентификации объектов и их значений.
Внутренняя логика Модели и Курсоров, а также способы ее реализации — тема отдельной статьи.
Потенциал масштабируемости обеспечивается двумя факторами: изоляцией отдельного объекта, а также разделением действий пользователя на выборку и транзакцию.
При необходимости увеличить нагрузочную способность первое, что приходит в голову, это выделение из пула серверов отдельного мастер-сервера. Мастер-сервер хранит эталонную копию базы и занимается исключительно исполнением транзакций. Транзакции ему поступают от остальных серверов, занимающихся обслуживанием запросов пользователей и формированием выборок. Результаты исполнения - поток измененных версий объектов, мастер-сервер широковещательно раздает всем остальным серверам, обслуживающим выборку данных, попутно обеспечивая многократную репликацию базы данных.
Наличие существенной неоднородности логической связи объектов в базе данных (объекты можно сгруппировать в домены с сильной связанностью внутри домена и малым количеством связей за его пределами) позволяет распределить базу данных на несколько мастер-серверов, каждый из которых обслуживает свои группы доменов.
Детальный разбор конкретики реализации масштабирования выходит за пределы данной статьи, но сами ее принципы являются предметом для обсуждения.
Как это часто случается при изложении достаточно объемного материала, было пропущено много относительно мелких и второстепенных деталей. Так например, не были упомянуты: сегментирование и дублирование DAT в памяти; особый порядок управления "большими" объектами; принципы организации взаимных блокировок потоков пользователей при доступе к общим ресурсам; логика и реализация сборки мусора; отображение процесса исполнения в log-журнал; сбор и отображение статистики; и многое другое.
Важно было показать, что много-поточное управление объектами опирается на достаточно тривиальную логику и не является такой уж сложной в реализации задачей.
Вариант реализации, доведенный до примитивизма, вероятнее всего окажется самым эффективным и производительным. Хотя в этом вопросе мнения могут и разделиться. Объектное представление данных выглядит более естественным, чем табличное. Упрощение внутренней идентификации обеспечивает "шаговую" доступность объектов, и сулит определенный профит при реализации их логической связи. Материал публикуется с надеждой, что будет полезен всем, кто интересуется архитектурой баз данных.